Lambda architecture is a data processing architecture designed to handle massive quantities of data by taking advantage of both batch and stream processing methods. The architecture was introduced by Nathan Marz and is based on three layers: the Batch Layer, the Speed Layer, and the Serving Layer.
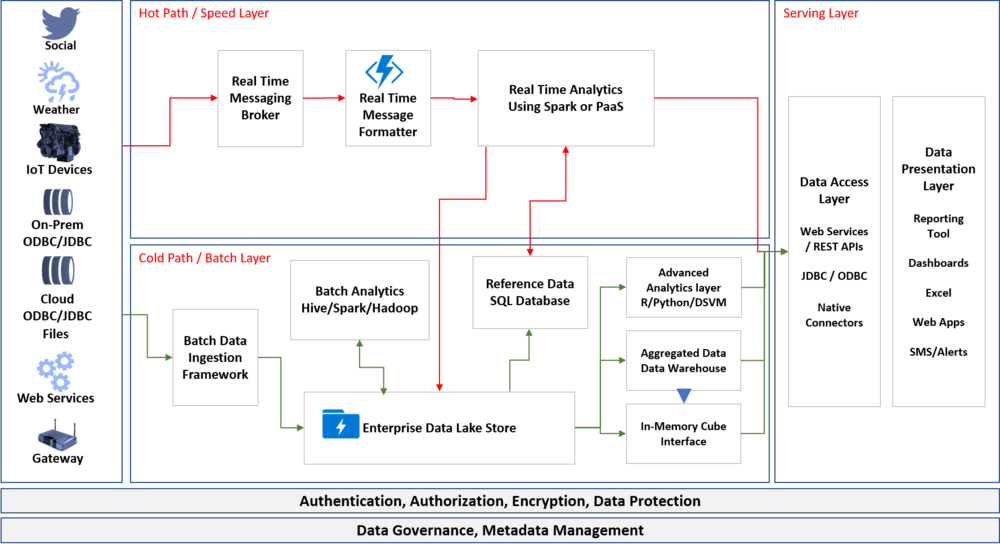
Batch Layer
The batch layer manages the master dataset (an immutable, append-only set of raw data) and pre-computes the batch views. The batch layer is designed to be fault-tolerant and capable of handling large volumes of data.
Key characteristics:
- Stores the complete, immutable dataset
- Recomputes views from scratch periodically
- Optimized for throughput, not latency
Speed Layer
The speed layer compensates for the high latency of the batch layer by processing data in real time. It only deals with recent data and provides low-latency updates to the serving layer.
Key characteristics:
- Processes only recent data
- Provides real-time views
- Optimized for low latency
Serving Layer
The serving layer indexes the batch views so they can be queried in low-latency, ad-hoc fashion. It merges results from both the batch and speed layers to provide a complete view of the data.
When to Use Lambda Architecture
Lambda is well-suited for scenarios where:
- You need both historical and real-time analysis
- Fault tolerance and reprocessing capability are important
- You can tolerate some complexity in maintaining two separate processing paths
The main trade-off is operational complexity — maintaining two separate codebases (batch and streaming) for the same business logic.
See also: Kappa Architecture and Delta Architecture for alternative approaches.